字符编码浅析 Markdown
以前对各种编码也是一知半解,现系统学习,记录如下。
#相关背景 ##拉丁字母
拉丁字母也叫罗马字母,ABCD……就属于最常见的26个拉丁字母。早期欧洲使用,后来由于欧洲殖民主义,导致美洲也使用这套字母体系,现在受西方文化影响许多,许多国家都使用这套字母体系,中国的汉语拼音使用的也是这个拉丁字母。
##字符编码
简而言之,就是将字符映射成计算机中的0和1二级制串。如97=0x61=01100001='A',就属于我们常见的ASCII编码中大写A的编码。那这个映射关系到底是怎样的呢,我们能不能建立一个自己的映射关系来编码字符呢?答案是可以的,只是首先你要让业界都认同。
#字符编码的标准 ##ASCII编码=ISO/IEC 646 ###ASCII的由来 ASCII全称American Stardard Code for Information Interchange,美国信息交换标准代码。因为计算机是美国人发明的,这就是最初美国人给字符的编码方式,供自己使用。所以只能显示常见的英文字符,不包括欧洲很多国家的衍生的拉丁字母,更不会有中文字符集这么一说。因此才会有后面提到的许多编码方式,目的就是为了计算机能显示自己国家的语言。
###ASCII的编码规则 ASCII的编码只考虑了英文字母系统,而英文只有26个字母,加上其大小写,再加上数字,常见字符标点等,也就几十个。而一个字节8位中的前7位能表示$2^7=128$,所以只用一个字节表示就足够了,ASCII编码中规定最高位为0,其他7位对应的值映射到某个字符。
其中表示的128个字符=33个不可显示字符+95个可显示字符。 ####ASCII字符代码表 不可见字符都是一些控制字符,如换行回车、传输开始结束等,不会被显示的打印出来。

上图中,如0010=2表示的字符表示‘正文开始’,可按Ctrl+B输入显示出的字符是个“笑脸”,这个“笑脸”没有什么实际意义,只是提示你你按了这个字符了。显示如下:

再如,111 1111=127=DEL,因为在最初的穿孔纸带上,一个字符对应着7个孔,打孔就代表1,如果7个孔全打了,说明这个字符就不要了,被删除了。因为打孔的过程是不可逆的。
各个字符的作用在此不一一枚举。
##支持多种衍生拉丁字母的EASCII和ISO8859 随着计算机发展到欧洲,欧洲许多国家除了用ASCII码中的哪些拉丁字母之外,还有些衍生的拉丁字母,且不同国家还不相同。所以设计了一个新的编码标准支持哪些衍生的拉丁字母且兼容旧的ASCII编码。
这里有两个标准,EASCII编码标准和国际标准ISO 8859。
###EASCII编码
ASCII编码中只用了低7位,最高位为0,现在将第八位也用上,用0xA0-0xFF <=> 1010 0000-1111 1111这部分来表示扩充出来的编码,如希腊字母,拉丁符号等。但是EASCII虽然解决了这些西欧语言的字符显示问题,但对于其他语言,依然无法显示。
目前,很少使用EASCII,常用的是下面介绍的ISO 8859。
###ISO/IEC 8859编码
ISO/IEC 8859也是同扩展ASCII中的最高位,主要是在ASCII中的普通可见字符0x20-0x7E=0010 0000-0111 1110的基础上,将最高位设为1,所以0xA0-0xFF为编码使用。
有别于ASCII单个编码的规则,ISO/IEC 8859是一组编码规则的总称,其下包含了15个字符集,每个字符集编码取值都是从0xA0-0xFF。这是因为欧洲国家衍生的字符集总和较多,就算将ASCII全部扩充也只能多表示128个字符,这也是不够的。所以设计了多个字符集,这样用一个字节也能表示,节约存储空间,坏处就是比如你写一篇文章,里面用到了多个国家的语言体系下的特殊字符,这样就无法用ISO/IEC 8859全部显示。
再来说个与ISO/IEC 8859相关的编码内容。
###ISO/IEC 6429编码
ISO/IEC 6429重新定义了ASCII中的0x00-0x1F即控制字符部分,另外还利用了ISO/IEC 8859编码没有利用的0x80-0x9F部分。相关内容的记录较少。
##几乎支持世界上所有字符的字符编码:Unicode
(还是那个开头)随着计算机的发展,亚洲以及世界各个国家也遇到同样问题,如何将自己国家的字符显示在屏幕上。
Unicode有道翻译为万国码。
Unicode为什么能涵盖各个国家的字符呢,原因很简单,多个字节。使用了多文本平面划分。
###Unicode字符编码所对应的存储和交换标准:UTF-8,UTF-16,UTF-32 需要注意的是,Unicode只是一个符号集合,它规定了符号的二进制代码,却没有规定二进制代码应该如何存储,如果让每个英文字母都用两个字节存储,那么一篇英文文章的大小将要增加一倍,网络传输的所需要的流量也要增加一倍。
####UTF-8 随着互联网普及,UTF-8是使用最广的一种Unicode的实现方式。最大的特点是它是一种变长的编码方式。它使用1-4个字节表示一个符号,根据不同的符号变化字节长度。
Unicode与Utf-8(8-bit Unicode Transformation Format)之间的编码映射关系表:
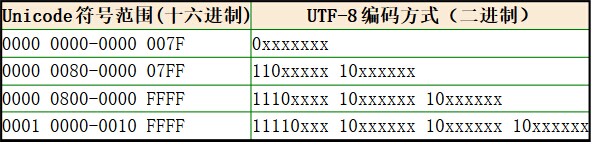
将字符的Unicode码与上表对比,找到对应的UTF-8编码的字节数。 UTF-8的编码规则:
- 对于单字节符号,最高位设为0,后7位为这个字符的Unicode码。
- 对于n(n>1)字节的符号,第一个字节的前n位设为1,n+1位设为0,后面字节的前两位一律设为
10。如字符是3字节符号,则对应的UTF-8编码为1110xxxx 10xxxxxx 10xxxxxx。如“严”的Unicode是4E25=10 0110 0010 0101,根据上表属于3字节范围。则严的UTF-8编码是11100100 10111000 10100101。转换成十六进制就是E4B8A5。
实验:在nodepad中输入“严”,保存为Unicode编码,换成16进制模式显示FF FE 25 4E,其中FF FE表示以小头方式存储(大头方式是FE FF),真正编码是4E25,另存为UTF-8编码格式,发现对应编码变为了
E4 B8 A5。
在c语言,如果采用utf-8编码,运行结果是4(已测)。
//{c}
#include<string.h>
#include<stdio.h>
int main(void)
{
char *s="a是";
printf("%d",strlen(s));
getchar();
return 0;
}
###GB2312
主要是针对中国人使用的汉字的一种编码方式,规定小于127,即0x00-0x7F编码与ASCII相同,当两个大于127的字符连在一起时,就表示一个汉字,从高字节0xA1-0xF786个组合(高位为1,低位为内码部分,即不算控制字符0x00-0x20),低字节0xA1-0xFE93种组合,这样我们能表示86*93=7998(题外话:Markdown用*一定要用\转义,否则Github Pages报错找半天)种字符>6000多个常用汉字,因为就足够剩余,在编码中,还把数学符号、希腊罗马字母、日本平假名都编进去了,包括中文的标点符号,都用两个字节编码,这就是常说的“全角”字符,而原来那些就叫“半角”字符。所以GB2312是ASCII的中文扩展。
那一个大于127的字符和一个小于127的字符组合在一起会怎么样呢?(EditPlus无法编辑,以后尝试)
###GBK 后来中国汉字增多了,许多人名字打不出来,就又把GB2312扩充,不要求低字节是127之后的内码了,只要大于127就表示一个汉字的开始,这样能多表示,这样能多表示将近20000多个新汉字了(包括繁体字)。GBK完全包括GB2312。
###GB18030 又在GBK的基础上增加了几千个少数民族的字。
#Over 以上知识点都是本人上网查找总结的,欢迎大家讨论交流。
blog comments powered by Disqus